
Дубли – это страницы сайта с одинаковым или практически полностью совпадающим контентом. Наличие таких страниц может негативно сказаться на взаимодействии сайта с поисковой системой.
Среди негативных последствий:
- Замедление индексирования нужных страниц. Если на сайте много одинаковых страниц, робот будет посещать их все отдельно друг от друга. Это может повлиять на скорость обхода нужных страниц, ведь потребуется больше времени, чтобы посетить именно нужные страницы.
- Затруднение интерпретации данных веб-аналитики. Страница из группы дублей выбирается поисковой системой автоматически, и этот выбор может меняться. Это значит, что адрес страницы-дубля в поиске может меняться с обновлениями поисковой базы, что может повлиять на страницу в поиске (например, узнаваемость ссылки пользователями) и затруднит сбор статистики.
Если на сайте есть одинаковые страницы, они признаются дублями, и в поиске тогда будет показываться по запросу только одна страница. Но адрес этой страницы в выдаче может меняться по очень большому числу факторов. Данные изменения могут затруднить сбор аналитики и повлиять на поисковую выдачу.
Дубли могут появиться на сайт в результате автоматической генерации, например, когда CMS сайта создает ссылки не только с ЧПУ, но и техническим адресом. Или в результате некорректных настроек. К примеру, при неправильно настроенных относительных ссылках на сайте могут появляться ссылки по адресам, которых физически не существует, и они отдают такой же контент, как и нужные страницы сайта. Или на сайте не настроена отдача HTTP-кода ответа 404 для недоступных страниц — от них приходит «заглушка» с сообщением об ошибке, но они остаются доступными для индексирования.
Как их обнаружить?
Теперь находить одинаковые страницы стало проще: в разделе «Диагностика» Яндекс.Вебмастера появилось специальное уведомление, которое расскажет про большую долю дублей на вашем сайте. Алерт появляется с небольшой задержкой в 2-3 дня — это обусловлено тем, что на сбор достаточного количества данных и их обработку требуется время. С этим может быть связано появление в нем исправленных страниц. Подписываться на оповещения не нужно, уведомление появится само.
А если нужно найти дубли вручную, в кабинете Вебмастера, во вкладке «Индексирование» есть раздел «Страницы в поиске», там нужно нажать на «Исключённые» в правой части страницы:
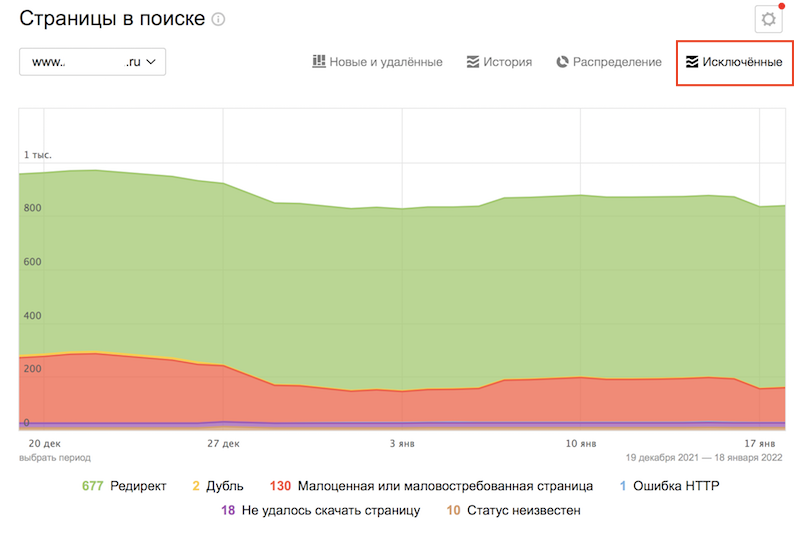
Прокрутив вниз, в правом нижнем углу можно увидеть опцию «Скачать таблицу». Выбрав подходящий формат можно загрузить архив. В скачанном файле у страниц-дублей будет статус DUPLICATE.
Как оставить в поиске нужную страницу в зависимости от ситуации
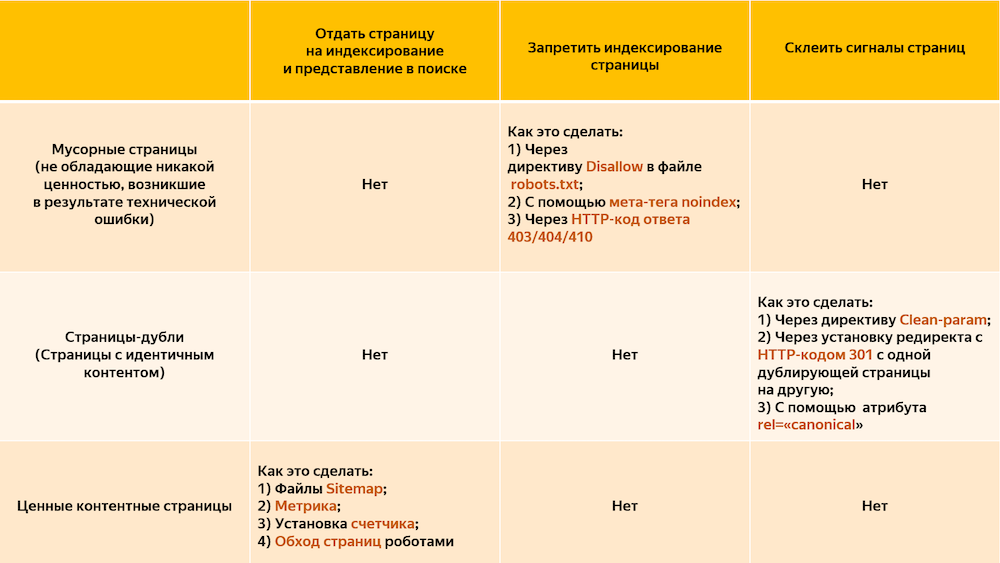
1. Добавить в файл robots.txt директиву Clean-param, чтобы робот не учитывал незначащие GET-параметры в URL. Робот Яндекса, используя эту директиву, не будет много раз обходить повторяющийся контент. Значит, эффективность обхода повысится, а нагрузка на сайт снизится.
2. Если нет возможности добавить директиву Clean-param, нужно указать канонический адрес страницы, который будет участвовать в поиске. Это не уменьшит нагрузку на сайт: роботу Яндекса все равно придется обойти страницу, чтобы узнать о rel=canonical. Поэтому рекомендуется использовать Сlean-param как основной способ.
3. Если по каким-то причинам предыдущие пункты не подходят, можно просто закрыть дубли от индексации при помощи директивы Disallow. Но в таком случае поиск Яндекса не будет получать никаких сигналов с запрещенных страниц. Поэтому все-таки лучше использовать Сlean-param как основной способ.
Подробнее о работе со страницами-дублями можно прочесть в Справке.